和lxml一样,BeautifulSoup也是一个HTML/XML的解析器,主要的功能也是解析和提取HTML/XML数据。
lxml只会局部遍历,而BeautifulSoup是基于HTML DOM的,它会加载整个文档,解析整个DOM树,因此在时间和内存上也会有很大的开销,所以性能要低于lxml。
BeautifulSoup用来解析HTML比较简单,其API设计的非常人性化,同时BeautifulSoup也支持CSS选择器、Python标准库中的HTML解析器、lxml的XML。
安装:pip install bs4
中文文档:https://www.crummy.com/software/BeautifulSoup/bs4/doc/index.zh.html
对比:
解析工具
解析速度
使用难度
BeautifulSoup4
最慢
最简单
lxml
快
简单
正则
最快
最难
简单使用 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 from bs4 import BeautifulSouphtml = """ <html><head><title>The Dormouse's story</title></head> <body> <p class="title"><b>The Dormouse's story</b></p> <p class="story">Once upon a time there were three little sisters; and their names were <a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>, <a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and <a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>; and they lived at the bottom of a well.</p> <p class="story">...</p> """ soup = BeautifulSoup(html, 'lxml' ) print (soup.prettify())
BeautifulSoup(markup, features):在使用的时候需要指定解析器,如果未指定,BeautifulSoup使用的Python标准库中的HTML解析器,同时beautifulsoup也支持第三方的解析器如lxml。另一个可供选择的解析器是纯Python实现的html5lib,html5lib的解析方式与浏览器相同。
安装lxml:pip install lxml
安装html5lib: pip install html5lib
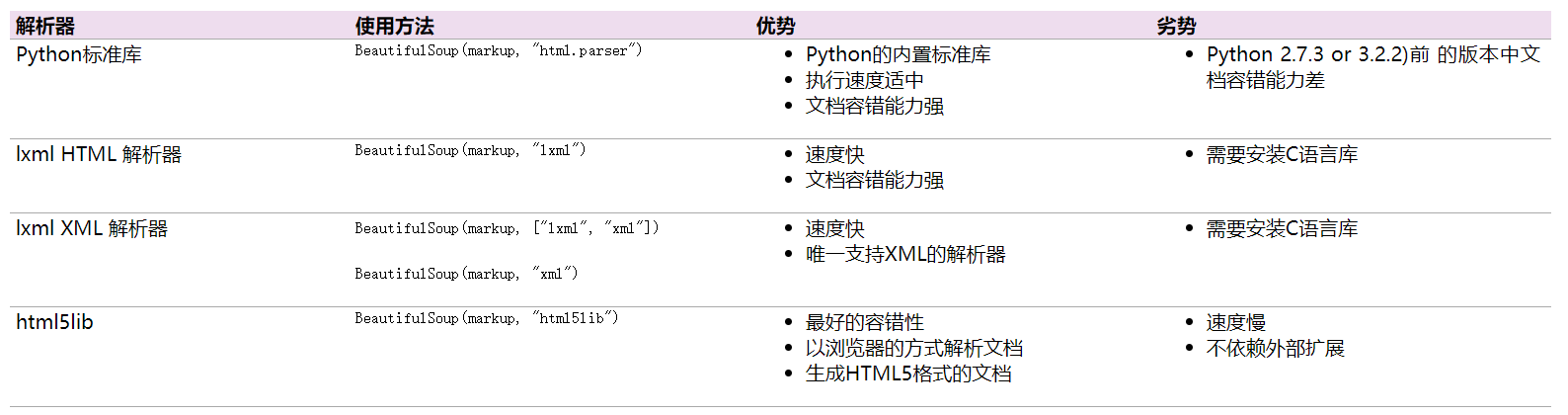
主要解析器的优缺点:
四个常用的对象 BeautifulSoup将复杂HTML文档转换成一个复杂的树形结构,每个节点都是Python对象,所有对象可以归纳为4种:
Tag
NavigatableString
BeautifulSoup
Comment
操作讲解 以下内容以4个例子的形式进行讲解:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 from bs4 import BeautifulSouphtml = """ <div data-v-a6e3291a="" class="correlation-degree"> <div data-v-a6e3291a="" class="recruit-wrap recruit-margin"> <div data-v-a6e3291a="" class="recruit-list"> <a data-v-a6e3291a="" class="recruit-list-link"> <h4 data-v-a6e3291a="" class="recruit-title">TEG15-计费产品web前端开发工程师(深圳)</h4> <p data-v-a6e3291a="" class="recruit-tips"> <span data-v-a6e3291a="">TEG</span> | <span data-v-a6e3291a="">深圳,中国</span> | <span data-v-a6e3291a="">技术</span> | <span data-v-a6e3291a="">2019年06月28日</span> </p> <p data-v-a6e3291a="" class="recruit-text">负责腾讯计费平台基础支付前端架构设计和开发工作; 参与需求评审、架构设计、编码设计和上线运维; 负责用户体验优化,包括但不限于:业务流程、前端展示、性能、安全等。</p> </a> <div data-v-a6e3291a="" class="recruit-collection"> <span data-v-a6e3291a="" class="icon-collection"></span> <span data-v-a6e3291a="" class="collection-text">收藏</span> </div> </div> <div data-v-a6e3291a="" class="recruit-list"> <a data-v-a6e3291a="" class="recruit-list-link"> <h4 data-v-a6e3291a="" class="recruit-title">PCG19-腾讯视频媒资后台开发工程师</h4> <p data-v-a6e3291a="" class="recruit-tips"> <span data-v-a6e3291a="">PCG</span> | <span data-v-a6e3291a="">北京,中国</span> | <span data-v-a6e3291a="">技术</span> | <span data-v-a6e3291a="">腾讯视频</span> | <span data-v-a6e3291a="">2019年06月28日</span> </p> <p data-v-a6e3291a="" class="recruit-text">负责腾讯视频媒资中台开发工作。</p> </a> <div data-v-a6e3291a="" class="recruit-collection"> <span data-v-a6e3291a="" class="icon-collection"></span> <span data-v-a6e3291a="" class="collection-text">收藏</span> </div> </div> <div data-v-a6e3291a="" class="recruit-list"> <a data-v-a6e3291a="" class="recruit-list-link"> <h4 data-v-a6e3291a="" class="recruit-title">TEG15-计费系统前端测试工程师(深圳)</h4> <p data-v-a6e3291a="" class="recruit-tips"> <span data-v-a6e3291a="">TEG</span> | <span data-v-a6e3291a="">深圳,中国</span> | <span data-v-a6e3291a="">技术</span> | <span data-v-a6e3291a="">2019年06月28日</span> </p> <p data-v-a6e3291a="" class="recruit-text">负责web端/后台系统测试工作,从整个项目角度规划测试方法,达成项目质量目标; 负责web端/后台系统的自动化测试、性能测试,稳定性以及其它专项测试; 负责研究web端/后台系统测试技术,跟进业界测试技术发展,引进先进测试方法并开展二次开发,建立团队质量体系建设,有效提升测试效率</p> </a> <div data-v-a6e3291a="" class="recruit-collection"> <span data-v-a6e3291a="" class="icon-collection"></span> <span data-v-a6e3291a="" class="collection-text">收藏</span> </div> </div> <div data-v-a6e3291a="" class="recruit-list"> <a data-v-a6e3291a="" class="recruit-list-link"> <h4 data-v-a6e3291a="" class="recruit-title">32032-资深后台开发工程师(上海)</h4> <p data-v-a6e3291a="" class="recruit-tips"> <span data-v-a6e3291a="">IEG</span> | <span data-v-a6e3291a="">上海,中国</span> | <span data-v-a6e3291a="">技术</span> | <span data-v-a6e3291a="">2019年06月28日</span> </p> <p data-v-a6e3291a="" class="recruit-text">游戏服务器的功能开发和现有系统的持续优化; 负责服务器压力测试和性能优化; 负责服务器外网运营的持续跟进和优化。 </p> </a> <div data-v-a6e3291a="" class="recruit-collection"> <span data-v-a6e3291a="" class="icon-collection"></span> <span data-v-a6e3291a="" class="collection-text">收藏</span> </div> </div> <div data-v-a6e3291a="" class="recruit-list"> <a data-v-a6e3291a="" class="recruit-list-link"> <h4 data-v-a6e3291a="" class="recruit-title">WXG03-搜索自然语言算法工程师</h4> <p data-v-a6e3291a="" class="recruit-tips"> <span data-v-a6e3291a="">WXG</span> | <span data-v-a6e3291a="">广州,中国</span> | <span data-v-a6e3291a="">技术</span> | <span data-v-a6e3291a="">2019年06月28日</span> </p> <p data-v-a6e3291a="" class="recruit-text">负责包括新词发现、命名实体识别、查询理解、意图提取、知识图谱、搜索喜好偏向性等相关系统的建设,用以优化微信小程序搜索各产品方向的流量分发,并参与工程实践。</p> </a> <div data-v-a6e3291a="" class="recruit-collection"> <span data-v-a6e3291a="" class="icon-collection"></span> <span data-v-a6e3291a="" class="collection-text">收藏</span> </div> </div> <div data-v-a6e3291a="" class="recruit-list"> <a data-v-a6e3291a="" class="recruit-list-link"> <h4 data-v-a6e3291a="" class="recruit-title">WXG03-搜索检索算法工程师</h4> <p data-v-a6e3291a="" class="recruit-tips"> <span data-v-a6e3291a="">WXG</span> | <span data-v-a6e3291a="">广州,中国</span> | <span data-v-a6e3291a="">技术</span> | <span data-v-a6e3291a="">2019年06月28日</span> </p> <p data-v-a6e3291a="" class="recruit-text">负责微信小程序搜索各个产品方向的检索工作,内容包括页面识别、页面核心数据提取、页面分类、页面评分、词权重、排序等相关工作,并与开发工程师配合进行工程实践。 </p> </a> <div data-v-a6e3291a="" class="recruit-collection"> <span data-v-a6e3291a="" class="icon-collection"></span> <span data-v-a6e3291a="" class="collection-text">收藏</span> </div> </div> <div data-v-a6e3291a="" class="recruit-list"> <a data-v-a6e3291a="" class="recruit-list-link"> <h4 data-v-a6e3291a="" class="recruit-title">23486-证券业务C++后台开发高级工程师(深圳)</h4> <p data-v-a6e3291a="" class="recruit-tips"> <span data-v-a6e3291a="">CDG</span> | <span data-v-a6e3291a="">深圳,中国</span> | <span data-v-a6e3291a="">技术</span> | <span data-v-a6e3291a="">2019年06月28日</span> </p> <p data-v-a6e3291a="" class="recruit-text">负责证券交易、风控、清算等系统的开发维护,建设证券业务相关的技术基础平台。</p> </a> <div data-v-a6e3291a="" class="recruit-collection"> <span data-v-a6e3291a="" class="icon-collection"></span> <span data-v-a6e3291a="" class="collection-text">收藏</span> </div> </div> <div data-v-a6e3291a="" class="recruit-list"> <a data-v-a6e3291a="" class="recruit-list-link"> <h4 data-v-a6e3291a="" class="recruit-title">22989-腾讯云数据平台产品中心运营开发</h4> <p data-v-a6e3291a="" class="recruit-tips"> <span data-v-a6e3291a="">CSIG</span> | <span data-v-a6e3291a="">深圳,中国</span> | <span data-v-a6e3291a="">技术</span> | <span data-v-a6e3291a="">2019年06月28日</span> </p> <p data-v-a6e3291a="" class="recruit-text">负责腾讯云数据平台产品的设计和研发。 负责云产品数据管理和服务的设计和研发。 负责构建和完善云底层数据的存储和查询,优化数据的质量和监控能力。</p> </a> <div data-v-a6e3291a="" class="recruit-collection"> <span data-v-a6e3291a="" class="icon-collection"></span> <span data-v-a6e3291a="" class="collection-text">收藏</span> </div> </div> <div data-v-a6e3291a="" class="recruit-list"> <a data-v-a6e3291a="" class="recruit-list-link"> <h4 data-v-a6e3291a="" class="recruit-title">18428-证券业务测试工程师</h4> <p data-v-a6e3291a="" class="recruit-tips"> <span data-v-a6e3291a="">CDG</span> | <span data-v-a6e3291a="">北京,中国</span> | <span data-v-a6e3291a="">技术</span> | <span data-v-a6e3291a="">财付通</span> | <span data-v-a6e3291a="">2019年06月28日</span> </p> <p data-v-a6e3291a="" class="recruit-text">负责证券类产品的功能、性能、安全、自动化等测试工作,包括终端/H5及后台系统的测试。</p> </a> <div data-v-a6e3291a="" class="recruit-collection"> <span data-v-a6e3291a="" class="icon-collection"></span> <span data-v-a6e3291a="" class="collection-text">收藏</span> </div> </div> <div data-v-a6e3291a="" class="recruit-list"> <a data-v-a6e3291a="" class="recruit-list-link"> <h4 data-v-a6e3291a="" class="recruit-title">30360-后台平台开发(深圳)</h4> <p data-v-a6e3291a="" class="recruit-tips"> <span data-v-a6e3291a="">PCG</span> | <span data-v-a6e3291a="">深圳总部,中国</span> | <span data-v-a6e3291a="">技术</span> | <span data-v-a6e3291a="">2019年06月28日</span> </p> <p data-v-a6e3291a="" class="recruit-text">负责QQ平台海量用户和数据的基础后台研发工作; 负责AI基础架构系统后台研发工作; 负责推荐系统,大数据分析计算后台研发工作。</p> </a> <div data-v-a6e3291a="" class="recruit-collection"> <span data-v-a6e3291a="" class="icon-collection"></span> <span data-v-a6e3291a="" class="collection-text">收藏</span> </div> </div> </div> </div> """ soup = BeautifulSoup(html, 'lxml' )
获取所有的class属性为“recruit-list”的div标签
1 2 3 divs = soup.find_all('div' , attrs={'class' : "recruit-list" }) for div in divs: print (div)
获取第二个class属性为“recruit-list”的div标签
1 2 div = soup.find_all('div' , attrs={'class' : "recruit-list" }, limit=2 )[1 ] print (div)
获取所有的h4标签中的class属性
1 2 3 h4_texts = soup.find_all('h4' ) for h4_text in h4_texts: print (h4_text['class' ])
获取所有的职位信息(纯文本)
1 aEs = soup.find_all('a' )
方法一
输出的字符串中可能包含了很多空格或空行,使用 .stripped_strings 可以去除多余空白内容
1 2 3 for aE in aEs: infos = list (aE.stripped_strings) print (infos)
方法二
1 2 3 4 5 6 7 8 9 10 11 job = {} for aE in aEs: h4 = aE.find('h4' ).string ps = aE.find_all('p' ) spans = ps[0 ].find_all('span' ) span = '|' .join([s.string for s in spans]) p2 = ps[1 ].string job['title' ] = h4 job['info' ] = span job['desc' ] = p2 print (job)
方法三
该方法提取出的内容中包含换行、空格。
1 2 for aE in aEs: print (list (aE.strings))
_注意_:
strings和stripped_strings、string属性和get_text方法:
string:获取某个标签下的非标签字符串。返回值为字符串。
strings:获取某个标签下的所有非标签字符串,返回结果为一个生成器。
stripped_strings:获取某个标签下的所有非空行、非换行的非标签字符串,返回结果为一个生成器。
get_text:获取某个标签下的所有非标签字符串,返回结果为字符串。
搜索文档树 find和find_all方法 搜索文档树,一般采用较多的是这两个方法,一个是find,另一个是find_all方法。find方法是在文档树中找到第一个满足条件的标签后就返回结果。find_all方法是在文档树中找到所有满足条件的标签后返回结果。在这两个方法中最常用的用法是name和attr参数,其中也可以直接传入关键字,在传入关键字”class”时,需要将”class”变为”class_”。
1 soup.find_all('div' , class_="test" )
select方法 在使用css选择器的方式时,需要使用select方法。以下为几种常用的css选择器方法:
通过标签名查找
通过类名查找
通过类名,应该在前面加一个”.”,比如要查找class=sister的标签。
1 print (soup.select('.sister' ))
通过id查找
通过id查找,应该在id的名字前面加一个”#”号。
1 print (soup.select('#link1' ))
通过组合查找
组合查找时,标签名和类名、id名进行组合的方式进行查找,例如查找p标签中,id等于link1的内容。
1 print (soup.select("p #link1" ))
直接子标签查找,则用”>”分隔
1 print (soup.select("head > title" ))
通过属性查找
查找时还可以加入属性元素,属性元素需要使用中括号括起来,注意属性和标签属于同一节点,所以中间不能加空格,否则会无法匹配
1 print (soup.select('a[href="http://example.com/elsie"]' ))
获取内容
以上的select方法返回的结果都是以列表的形式返回的,可以进行遍历输出,然后使用get_text()方法获取其他的内容。
1 2 3 4 5 6 soup = BeautifulSoup(html, 'lxml' ) print (type (soup.select('title' )))print (soup.select('title' )[0 ].get_text())for title in soup.select('title' ): print (title.get_text())